

In my first article where I introduced bioinformatics, I have mentioned that we will be learning a lot about DNA, RNA and Protein sequences. Since I’m new to all these DNA/RNA jargon, I decided to learn about them first and then try out some coding problems. All the sequencing problems seem to have some words related to genetics. So first things first, let’s get started. 😊
Note: I assume you have a basic knowledge about chemistry, thereby assuming you know the meaning of terms such as hydrogen bonds, phosphate groups, hydroxyl groups, etc.
What is DNA?
DNA or deoxyribonucleic acid, is a molecule that carries the genetic code of all living organisms. DNA together with its freiend RNA or ribonucleic acidare known as nucleic acids. DNA is the structure where all the biological information of a living being is stored.
What are Nucleotides?
DNA is a long, chainlike molecule which has two strands twisted into a double helix. The two strands are made up of simpler molecules called nucleotides. Each nucleotide is composed of one of the four nitrogen-containing nucleobases,
- cytosine (C)
- guanine (G)
- adenine (A)
- thymine (T)
along with a sugar called deoxyribose, and a phosphate group.

These nucleobases are connected to one another in a chainlike structure by forming covalent bonds between the sugar of one nucleobase and the phosphate of the next, resulting in an alternating sugar-phosphate backbone. You can refer the diagram given above to get a clear understanding.
Representing a DNA Strand
A single DNA strand, formed by connecting nucleobases as discussed above, can be simply represented as given below. You can map this representation to the previous image. This will be one side of the molecule in the above image.
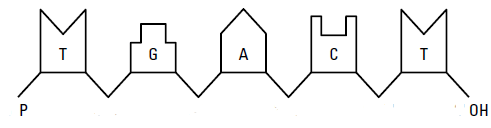
You may notice that there is an unused phosphoryl group at the left extreme (also called 5′-terminus) and an unused hydroxyl group at the right extreme (also called 3′-terminus). A DNA sequence of a single strand is always defined as a series of its constituent nucleotides listed in order from the unused phosphoryl group to the unused hydroxyl group. Above DNA sequence can be represented as,
TGACT = Thymine-Guanine-Adenine-Cytosine-Thymine
The two sides of a DNA Sequence
The nucleobases of the two separate strands are connected together, according to the base pairing rules; A with T and C with G, along with hydrogen bonds. DNA molecule consists of two complementary strands as shown below. The direction of reading the nucleotides is marked as well.

Complementarity means that the two strands follow the base pairing rules. Thymine (T) on one strand is always facing an adenine (A) and vice versa; guanine (G) is always facing a cytosine (C) and vice versa. When you know the sequence of nucleotides of one DNA strand, you can automatically deduce the sequence on the other strand.
The representations of the facing strands of the above DNA molecule will be,
TGACT and AGTCA
Time for some practice
I came across this interesting programming platform named Rosalind where you can learn bioinformatics and programming by solving the available problems. I will go through two of the problems which are related to what I have discussed in this article and explain how I solved them. I will be using my own examples for explanation. You can try them out from the link given above.
Counting DNA Nucleotides
Given a DNA sequence can be considered as a string with the alphabet {“A”, “C”, “G”, “T”}. We can count the number of times each letter appears in the string.
Given below is my solution in Python.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # Read the file and get the DNA string | |
| file = open('sample_dna.txt', 'r') | |
| dna = file.read() | |
| # Print the original DNA string | |
| print "DNA String: ", dna | |
| # Print the count of each letter | |
| print "Count of A: ", dna.count("A") | |
| print "Count of C: ", dna.count("C") | |
| print "Count of G: ", dna.count("G") | |
| print "Count of T: ", dna.count("T") | |
| # End of program |
My sample_dna.txt file contains the following DNA string.
GTAAACCCCTTTTCATTTAGACAGATCGACTCCTTATCCATTCTCAGAGATGTGTTGCTGGTCGCCG
Given below is the output.

We can read the DNA string from a file and then use the string count method of Python to count how many times each letter has occurred. You can also iterate the string in a loop and maintain counts for each letter separately.
Complementing a Strand of DNA
Recall what we have learned about the complementary strands of a DNA molecule. This question is about finding the sequence of the other facing strand.
Given below is my solution in Python.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # Read the file and get the DNA string | |
| file = open("sample_dna.txt", "r") | |
| dna = file.read() | |
| # Print the original DNA string | |
| print "DNA String: ", dna | |
| # Create dictionary of complementing nucleobase pairs | |
| comp_pairs = {"A" : "T", "T" : "A", "G" : "C", "C" : "G"} | |
| complementing_strand = "" | |
| # Generate the complementing strand | |
| for i in range (len(dna)-1, -1, -1): | |
| complementing_strand += comp_pairs[dna[i]] | |
| # Print the complementing strand | |
| print "Complement: ", complementing_strand | |
| # End of program |
My sample_dna.txt file contains the following DNA string.
AAAACCCGGTGTCTTATATCGAGTCATGCAATTTTGGG
Given below is the output.

In this solution I have iterated through the string in reverse and replaced A with T, T with A, G with C and C with G, to obtain the complementing DNA string.
Final Thoughts
DNA sequences and related data are stored in huge databases and are used in different fields such as Forensics, Genealogy and Medicine. These simple techniques will become the building blocks towards developing solutions for more complex problems.
Hope you enjoyed reading this article and learned something useful.
Since I’m still very new to this field, I would like to hear your advice. 😇
Thanks for reading… 😃
This post was originally posted by me in Medium.com
